

Son los más potentes hasta ahora y se pueden usar localmente
GoogleTras el salto tecnológico logrado con Gemini 3 Pro el año pasado, Google lleva ahora parte de esa investigación a la comunidad open-source con el lanzamiento de Gemma 4, su nueva familia de modelos open-weight más inteligente hasta la fecha.
Diseñados para razonamiento avanzado y flujos de trabajo agenticos, los nuevos modelos prometen una relación inédita de inteligencia por parámetro, ofreciendo capacidades de nivel frontera sin requerir hardware masivo.
Las generaciones anteriores ya habían superado los 400 millones de descargas y generado más de 100,000 variantes, y Gemma 4 busca ampliar ese ecosistema con herramientas aún más potentes para los desarrolladores.
Una familia versátil, del smartphone a la nube
Para adaptarse a distintos dispositivos y casos de uso, Gemma 4 llega en cuatro tamaños. En IA, los parámetros son los ajustes internos que determinan cómo el modelo genera resultados: más parámetros suelen implicar mayor calidad, pero también mayor demanda computacional.
Modelos para el edge: E2B y E4B
Pensados para móviles y dispositivos IoT, los modelos de 2B y 4B parámetros efectivos priorizan:
- Baja latencia
- Uso mínimo de RAM
- Ahorro de batería
Desarrollados junto a Qualcomm, MediaTek y el equipo de Pixel de Google, estos modelos pueden ejecutarse completamente offline en smartphones o incluso en las Raspberry Pi.
Modelos para estaciones de trabajo y la nube: 26B MoE y 31B Dense
Para cargas de trabajo más exigentes:
- Los pesos sin cuantizar caben en una sola GPU NVIDIA H100 de 80 GB.
- Las versiones cuantizadas pueden ejecutarse en GPUs gaming.
El modelo 26B Mixture of Experts (MoE) prioriza velocidad activando solo 3.8B parámetros durante inferencia.
El 31B Dense se enfoca en calidad máxima para fine-tuning.
En el ranking de texto de Arena AI, ambas variantes alcanzaron los puestos #3 y #6 entre modelos abiertos, superando sistemas hasta 20 veces más grandes.
Capacidades de nueva generación
Gemma 4 va mucho más allá del chat tradicional con funciones diseñadas para aplicaciones reales:
- Multimodal nativo: procesan video, imágenes, OCR y gráficos; los modelos edge incluyen entrada de audio.
- Workflows agenticos: soporte para function-calling, JSON estructurado e instrucciones del sistema.
- Generación de código offline: permite crear software sin conexión.
- Contexto masivo: hasta 128K tokens en edge y 256K en modelos grandes.
- Cobertura global: entrenamiento en más de 140 idiomas.
El gran cambio: licencia Apache 2.0
Uno de los anuncios más importantes es la adopción de la licencia Apache 2.0, mucho más permisiva que las licencias previas de la familia Gemma.
El movimiento responde al feedback de la comunidad y elimina barreras para uso comercial. El CEO de Hugging Face, Clément Delangue, calificó la decisión como un “gran hito” para el open-source.
Un ecosistema listo desde el día uno
Gemma 4 llega con soporte inmediato para herramientas populares como Hugging Face, LiteRT-LM, vLLM, Ollama y Google Cloud.
Los desarrolladores pueden descargar los pesos desde Hugging Face, Kaggle u Ollama y experimentar en Google AI Studio o desplegar a escala con Vertex AI, Cloud Run y TPUs.
Con Gemma 4, Google no solo ofrece una versión abierta de su IA avanzada: pone en manos de la comunidad una plataforma eficiente y poderosa para impulsar la próxima generación de aplicaciones inteligentes.
¿Cómo usar estos modelos de forma local?
Ollama, para mí es la solución más sencilla para poder correr modelos abiertos de forma local y está disponible para macOS, Windows y Linux.
Aunque Ollama tiene una interfaz gráfica que recuerda mucho a la de ChatGPT, muchas operaciones se deben hacer desde la línea de comando. Por ejemplo, bajar un nuevo modelo o actualizar un modelo, son tareas que se deben hacer desde la terminal.
Por eso, les recomiendo que utilicen un front-end gráfico para Ollama. Existen muchos, tanto para macOS como para Windows y Linux.
En el caso particular de macOS, una excelente opción para este tipo de tareas ya que los procesadores de Apple están especialmente diseñados para ellas, les recomiendo usar mi programa LocalIntelligence que no solo es un front-end gráfico para esa aplicación, sino que además incluye funcionalidad avanzada para ajustar los parámetros del modelo y soporte completo para MCP (Model Context Protocol), que es el protocolo en el que se basa la IA basa en agentes.
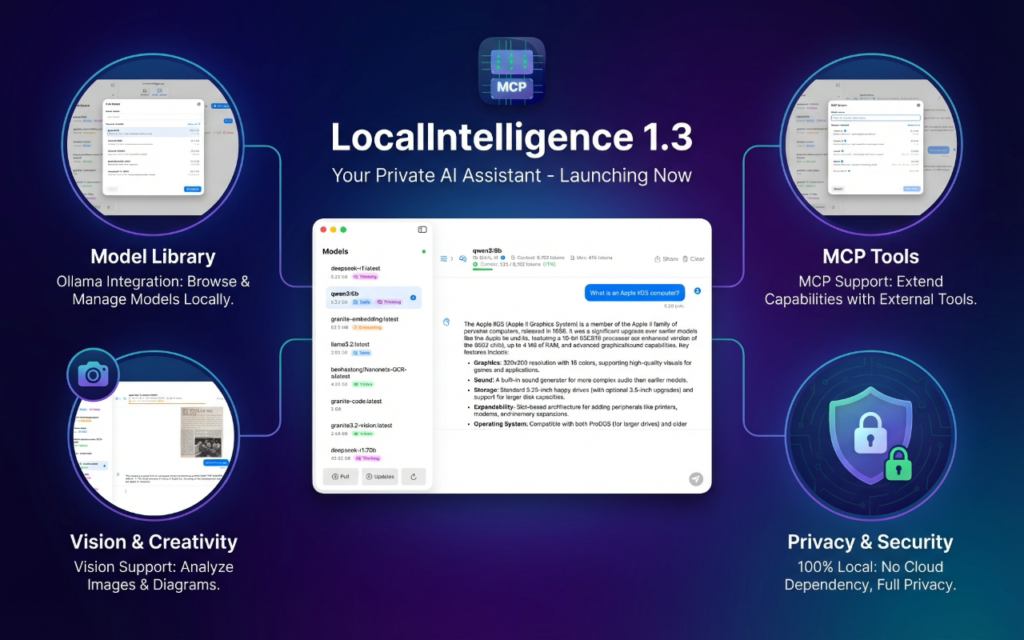
LocalIntelligence está disponible de forma gratuita en la App Store de Apple. Sin embargo, si van a usar un servidor MCP local, necesitarán bajar la versión notariada de mi página web personal, ya que esto requiere permisos adicionales que las aplicaciones del App Store no pueden obtener.